Библиотека Requests: HTTP for Humans
Автор: Python.Ru
Язык Python является универсальным языком программирования. С его помощью можно решать разнообразные задачи в сфере разработки.
Одной из таких сфер, в которой Python занял уверенную позицию, является веб-разработка. Немаловажную роль в этом сыграло обширное комьюнити, различные фреймворки и подключаемые библиотеки, созданные для облегчения жизни программистов. Об одной из таких библиотек сегодня пойдёт речь.
Библиотека Requests: HTTP for Humans
При решении различных задач в сфере веб-разработки, нам часто приходится взаимодействовать с HTTP. Это не самая простая задача для любого языка программирования и Python в этом не исключение. Язык, конечно, содержит встроенные модули, позволяющие отправлять HTTP запросы, но, как это ни парадоксально, их использование едва ли можно отнести к Pythonic-way.
В своё время чтобы обойти монструозность и сложность использования встроенных модулей появилась библиотека Requests. На данный момент она является одной из самых популярных библиотек на github: более 40 000 "звёзд" и используется более, чем в 20 000 open-source проектах. Нередко она используется и в коммерческой разработке.
Для чего и где мы можем применять Requests?
Как было отмечено выше, библиотека позволяет нам легко и с минимальным количеством кода взаимодействовать с веб-приложениями. Это необходимо нам для решения любых задач, связанных с передачей информации от пользователя к серверу и обратно. Но, чтобы что-то хорошо понять, необходимо закрепить теоретические знания практикой, поэтому перейдём от слов к делу.
Примеры использования библиотеки Requests
Для работы с примерами мы будем использовать два способа: работа в командной строке и написание скриптов в .py-файлах для их дальнейшего запуска.
Я показываю использование командной строки, так как это полезный навык, который пригодится в дальнейшем, когда надо будет быстро что-то проверить.
Для начала, поскольку библиотека является внешней, нам необходимо её установить. Делается это очень просто в командной строке:
$ pip install requests Продолжим использовать консоль. После установки в нашем расположении (у меня это диск D) введем команду:
D:\> python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 20:34:20) [MSC v.1916 64 bit (AMD64)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>>Теперь можем проверить установку библиотеки произведя импорт:
>>> import requests Получаем ответ от сайта
Первое, что мы сделаем - проверим статус-код ресурса. Иными словами: узнаем, работает ли сайт. Для этого мы создадим простой запрос GET. Подробнее с кодами состояния HTTP можно ознакомиться на сайте Веб-документация MDN.
>>> r = requests.get('http://learn.python.ru')Проверим, что возвращает нам данный запрос:
>>> r
<Response [200]>Как мы можем видеть, в качестве ответа мы получили объект класса Response и код 200. Этот код говорит, что ресурс работает и можно с ним взаимодействовать.
А что будет, если мы отправим неправильный запрос?
>>> r = requests.get('http://learn.python.ru/user')
>>> r
<Response [404]>Как вы можете заметить, этот запрос вернул нам всё тот же объект класса Response, но с другим кодом - 404. Это означает, что страницы ‘/user’ на сайте http://learn.python.ru нет.
Теперь, когда мы познакомились с тем, как отправлять запрос GET с помощью Requests, мы можем продвинуться дальше и сделать что-то более интересное.
Скачаем изображение с сайта
В этом примере мы будем применять всё тот же запрос GET, но, в отличие от предыдущего, мы будем работать с содержимым ответа.
>>> import requests
>>> image = requests.get('https://learn.python.ru/media/projects/sl1_Cj4bKxp.png')
>>> with open('new_image.png', 'wb') as f:
... f.write(image.content)После выполнения данного скрипта, мы увидим новое изображение под названием new_image.png в директории, из которой у нас запущен скрипт.
Подробнее с классом Response и методами получения его содержимого можно ознакомиться на официальном сайте библиотеки Requests.
Отправим сообщение в WhatsApp
В этом примере, в отличие от примеров выше, мы познакомимся с другим методом - POST. Стоит отметить, что запросы POST и GET являются самыми часто применяемыми при работе с HTTP.
Для реализации этого примера воспользуемся сервисом, предоставляющим API для отправки сообщений. Я буду использовать сервис Chat-Api. Это платный сервис, но у них есть демо-режим, предоставляющий бесплатный доступ на 3 дня, чего нам для реализации этой задачи будет достаточно. После регистрации на сайте и получении Api URL и токена, мы сможем выполнить отправку сообщений в WhatsApp. Вот что нам для этого потребуется:
>>> import requests
>>> url = '<Ваш API URL>/message?token=<Ваш токен>'
>>> data = {"phone": "<номер телефона, начинающийся с 7>", "body": "<текст сообщения>"}
>>> message = requests.post(url, json=data)И проверим, отправлено ли сообщение:
>>> print(message.text)Вы должны будете увидеть что-то вроде этого:
{"sent":true,"message":"<номер телефона адресата>@c.us","id":"true_<номер телефона адресата>@c.us_3EB07324DCD36BD13CC4","queueNumber":1}Загрузим файл на сервер
Для следующего примера воспользуемся сайтом для тестирования HTTP запросов Webhook.site. В качестве URL мы будем использовать ссылку, которая генерируется на сайте автоматически. У вас она будет отличаться от использованной в примере.
>>> import requests
>>> url = 'https://webhook.site/c253969f-1ad8-4888-812e-e57f4eb4924e'
>>> with open('test.txt', 'w') as f:
... f.write('текст для проверки загрузки файла')
>>> with open('test.txt', 'rb') as f:
... r = requests.post(url, {'files': f})
... print(r)После выполнения скрипта в терминале мы увидим уже знакомый нам объект класса Response и статус код - 200. Это означает, что запрос выполнился. Вернемся снова на сайт Webhook.site, выберем в правой колонке наш запрос и сможем посмотреть содержание выполненного запроса:
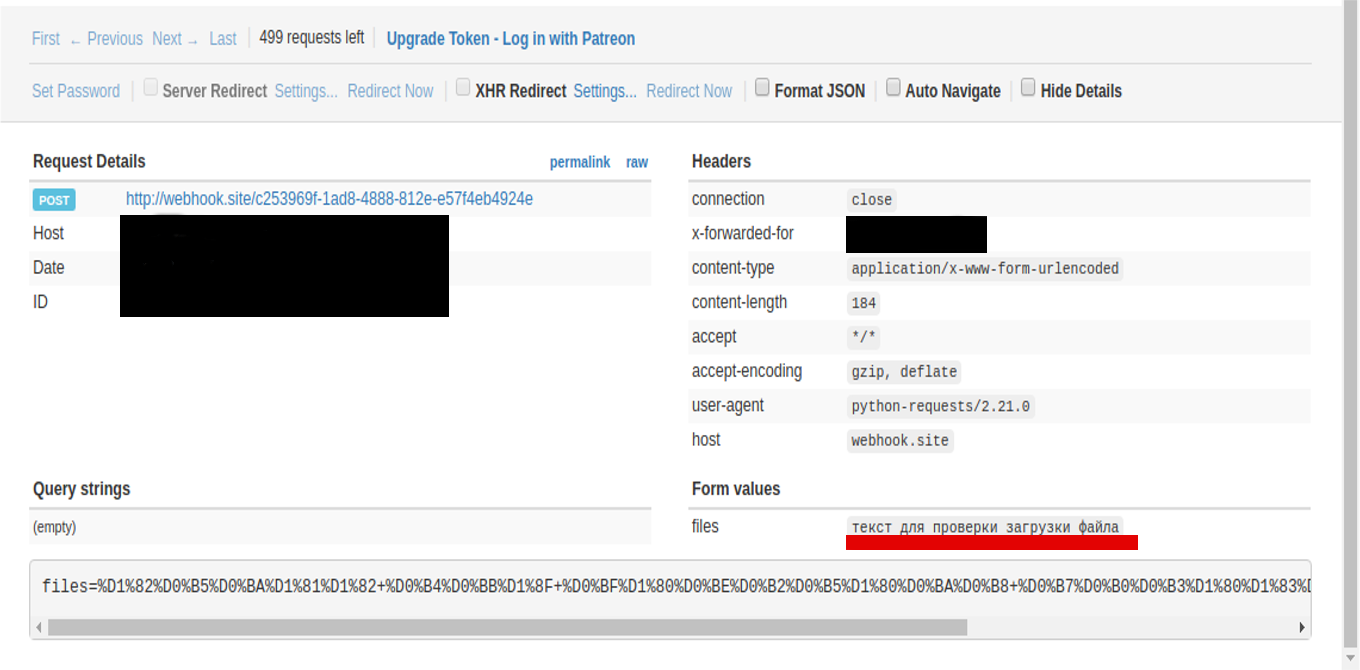
Авторизуемся на сайте
В этом примере будем использовать сайт, который нам также потребуется в следующем примере. Для начала зарегистрируемся на сайте WorldWeatherOnline. После удачной регистрации на сайте в личном кабинете вы увидите API KEY, который потребуется для следующего примера.
Для авторизации на сайте нам необходимо в запросе отправить пользовательские данные на сайт. Помимо логина и пароля, мы должны отправить сайту ключи, которые содержатся в заголовках пакета. Чтобы узнать эти ключи нужно выйти из нашей учётной записи, перейти на страницу входа, затем открыть в браузере Developer tools (F12), перейти на вкладку Network и снова авторизоваться. После того как страница загрузится в Developer tools во вкладке Network пролистайте вверх и найдите строчку login.aspx.
Как мы можем заметить во вкладке Headers, при входе мы осуществили запрос POST для передачи данных серверу. Пролистав вниз до блока Form Data, мы найдём все ключи, которые нам необходимо отправить сайту для авторизации.
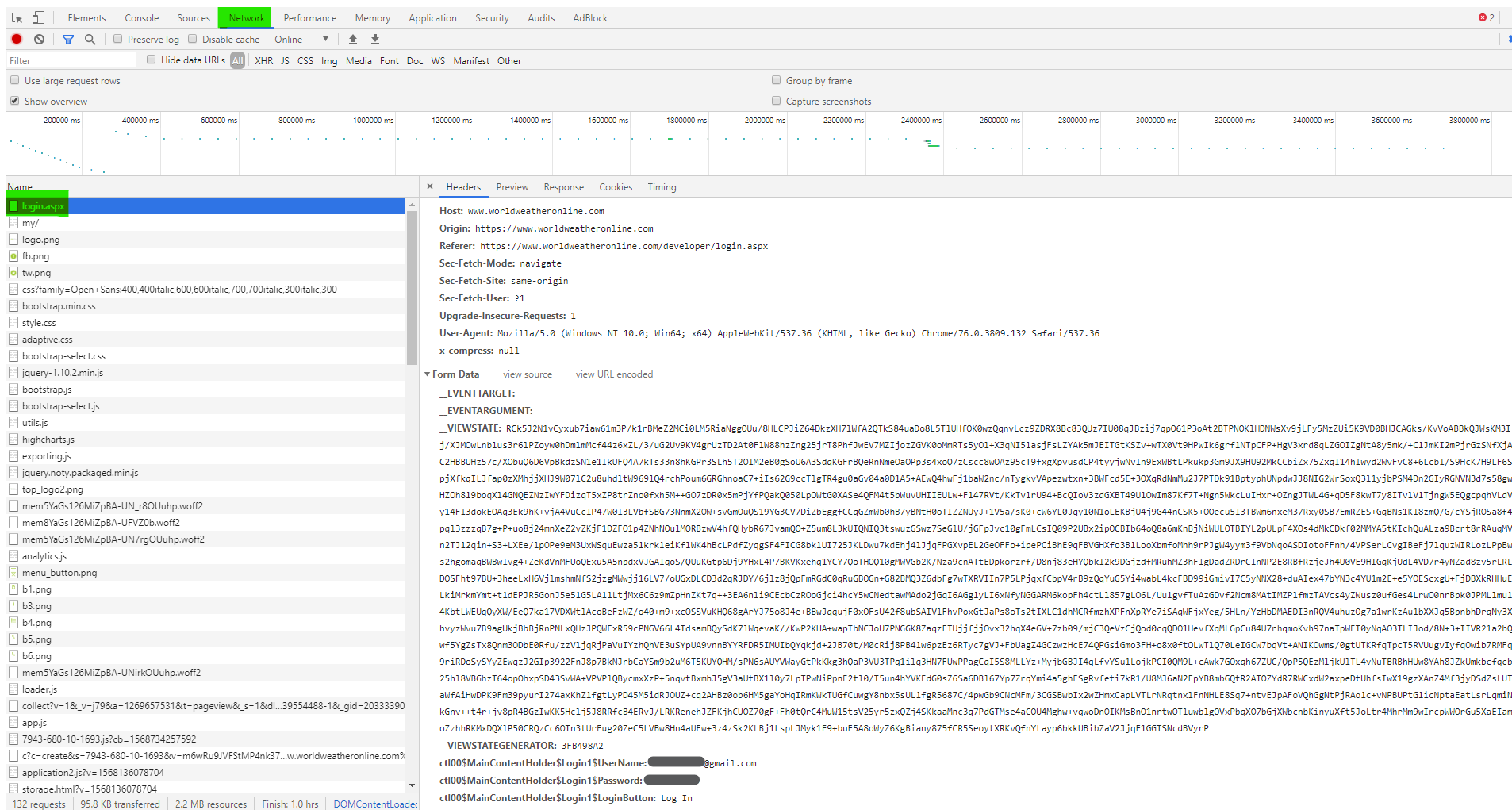
>>> import requests
>>> url = 'https://www.worldweatheronline.com/developer/login.aspx'
>>> data = {<заносим сюда все ключи, которые необходимо отправить серверу в формате “key”: “value” и не забываем ставить запятые после каждого “value”>}
>>> s = requests.Session()
>>> s = requests.post(url, data=data)Для проверки выполнения авторизации выведем содержание ответа сервера:
>>> print(s.text)После выполнения данной функции в консоли мы увидим содержимое страницы в виде текста, то есть так, как страницу “видит” наш браузер - в формате html. Подтверждением успешной авторизации служат следующие строки:
<li class="right_link"><a href="/developer/my/" class="bordered">My Account</a></li>
<li class="right_link"><a href="/developer/logout.aspx" class="bordered">Logout</a></li>Неавторизованному пользователю данные кнопки недоступны.
Узнаем погоду в Москве
В этом примере мы будем использовать API KEY с сайта WorldWeatherOnline, на котором мы зарегистрировались в прошлом примере. В разделе документации на сайте WorldWeatherOnline приведено подробное описание параметров.
Теперь уже с использованием вашей любимой IDE напишем скрипт, который будет принимать в качестве аргумента из командной строки город, а возвращать значение температуры.
Создадим файл и назовём его weather.py. Запишем в него:
import sys
import requests
def get_weather():
url = 'http://api.worldweatheronline.com/premium/v1/weather.ashx'
city = sys.argv[1]
params = { 'key': '<копируем сюда ключ, полученный на сайте>',
'q': city,
'format': 'json',
'num_of_days': 1,
'lang': 'ru'}
r = requests.get(url, params=params)
the_weather = r.json()
# данной строкой мы преобразуем полученное содержимое страницы
# в формат json, который очень похож на тип данных dict() в Python
# и с которым очень удобно работать
if 'data' in the_weather:
if 'current_condition' in the_weather['data']:
try:
return the_weather['data']['current_condition'][0]
except(IndexError, TypeError):
return 'Server Error'
return 'Server Error'
if __name__ == '__main__':
weather = get_weather()
print(f'Погода сейчас {weather["temp_C"]}, ощущается как {weather["FeelsLikeC"]}')Запустим наш скрипт в командной строке:
$ python weather.py Moscow В качестве ответа мы должны увидеть:
Погода сейчас 20, ощущается как 20 В этом примере мы не просто получили какую-то информацию от сервера, но и обработали содержимое полученного ответа. В следующем примере мы разберем еще один метод обработки полученного содержимого ответа.
Напишем простой парсер новостей
В качестве источника новостей будем использовать хаб о Python сайта Habr.com. В этом примере, помимо Requests нам также понадобится библиотека BeautifulSoup. С данной библиотеке можно подробно познакомиться на официальной странице документации Beautiful Soup. Устанавливается она также просто, как и Requests:
$ pip install beautifulsoup4 Создадим файл с названием news.py и запишем в него следующее:
import requests
from bs4 import BeautifulSoup
class HabrPythonNews:
def __init__(self):
self.url = 'https://habr.com/ru/hub/python/'
self.html = self.get_html()
def get_html(self):
try:
result = requests.get(self.url)
result.raise_for_status()
return result.text
except(requests.RequestException, ValueError):
print('Server error')
return FalseМетод get_html() класса HabrPythonNews с помощью библиотеки Requests отправляет наш запрос GET к сайту Habr.com и возвращает содержимое страницы в виде текста. Иными словами, мы получаем html страницы. Если мы посмотрим на содержимое страницы (ctrl + U в Google Chrome), то обнаружим там различные блоки, в которых содержится информация. Нас интересуют только заголовки новостей и ссылки на них. Чтобы извлечь нужную нам информацию из содержимого страницы, мы воспользуемся библиотекой Beautiful Soup. Нужный нам блок называется:
<h2 class="post__title">Давайте теперь добавим функцию для работы с этим блоком:
def get_python_news(self):
soup = BeautifulSoup(self.html, 'html.parser')
news_list = soup.findAll('h2', class_='post__title')
return news_listМетод get_python_news() возвращает нам все элементы страницы, с тегом
<h2 class="post__title">И добавим завершающий блок нашего класса:
if __name__ == "__main__":
news = HabrPythonNews()
print(news.get_python_news())Итоговый код должен выглядеть у нас так:
import requests
from bs4 import BeautifulSoup
class HabrPythonNews:
def __init__(self):
self.url = 'https://habr.com/ru/hub/python/'
self.html = self.get_html()
def get_html(self):
try:
result = requests.get(self.url)
result.raise_for_status()
return result.text
except(requests.RequestException, ValueError):
print('Server error')
return False
def get_python_news(self):
soup = BeautifulSoup(self.html, 'html.parser')
news_list = soup.findAll('h2', class_='post__title')
return news_list
if __name__ == "__main__":
news = HabrPythonNews()
print(news.get_python_news())При выполнении данного скрипта мы получим ссылки и заголовки новостей с первой страницы хаба. Изменяя параметры поиска
news_list = soup.findAll('h2', class_='post__title') мы можем получать различные значения.
В качестве заключения
Использование библиотеки Requests не ограничивается приведенными выше примерами. Данная библиотека является очень удобным инструментом для взаимодействия с HTTP. Продолжить знакомство с библиотекой можно на официальном сайте Requests.
Автор: Виталий Калинин